Here is the 80/20 info for big scalable, distributed systems 🗣️
1) Building an entry to your system is lowkey hard…
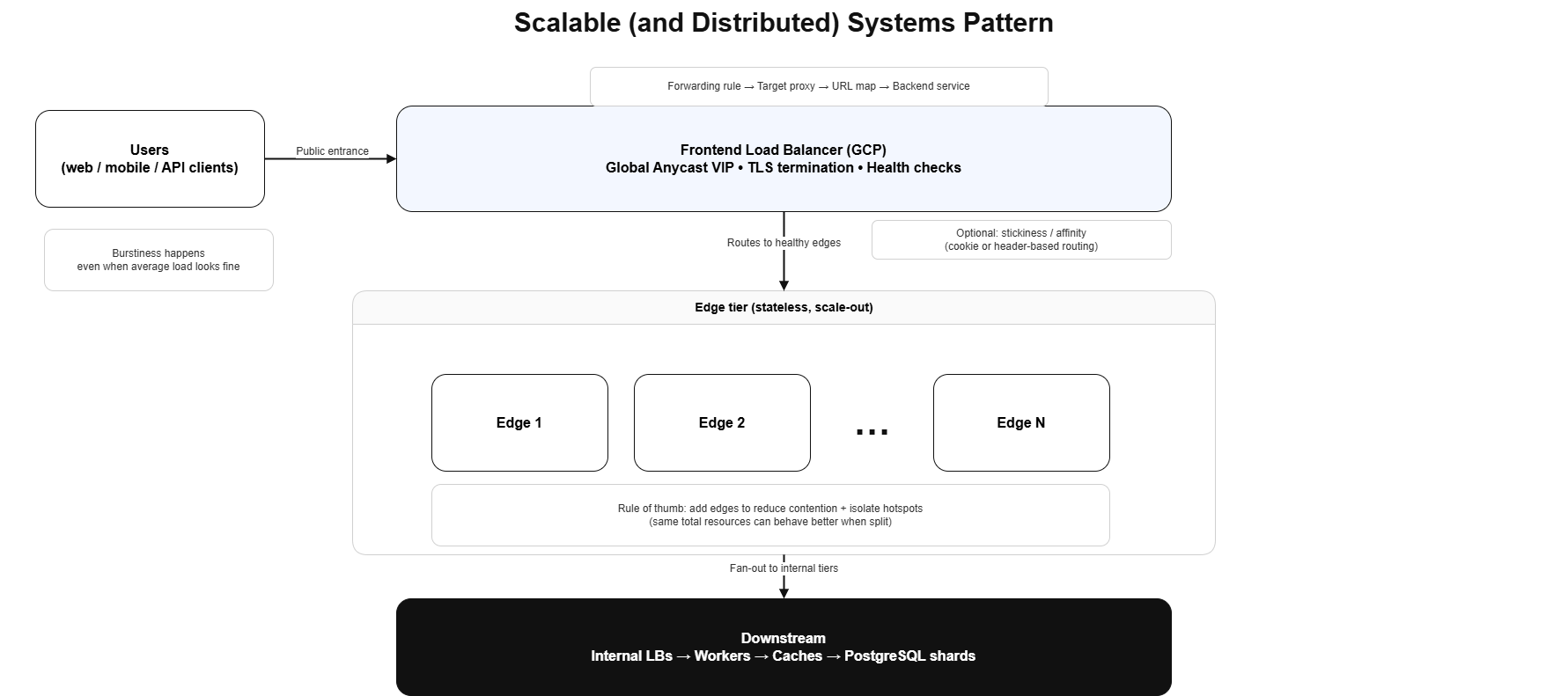
Most real systems end up with a single public entry point (DNS → LB → your stack).
The trick is: don’t build that entry tier yourself unless you have to. Hosted/global load balancers (example: Google Cloud) solve the hard parts:
- Anycast IP: users hit the nearest edge, not your one VM in one region
- Fully managed + scales fast: no “pre-warming” rituals
- Built on the same primitives Google uses internally: GFE / Maglev / Andromeda / Envoy ecosystem… Google some of this lol
Sometimes your “one entrance” should be boring, global, and managed.
2) Tail latency isn’t an endpoint problem, it’s a queueing problem
People talk about p95/p99 a lot (you already know). What actually affects those numbers is usually:
- Hidden queues: thread pools, connection pools, async executors
- Backpressure: or lack of it
- Retries/timeouts: amplifying overload
3) Request coalescing is dope
If 1,000 users ask for the same-ish thing at the same time, you can either:
- Do 1,000 downstream calls (and die), or
- Collapse duplicates (batch) and do far less work.
4) Why is horizontal scaling THE move
Splitting the same compute budget into multiple smaller instances can improve throughput and tail latency because:
- Less contention per process: GC, locks, pools stop fighting
- Smaller blast radius: when one instance goes weird
- Better load distribution: when combined with a real LB
Takeaway: “One big box” is simple… until it becomes one big bottleneck.
“Distributed” means multiple nodes coordinating over a network (and handling partial failures). “Big systems” are about scale/complexity. “Cloud” is just the platform you run it on.
Also here’s my quick draw.io visualization 🙃