Here is the 80/20 Of The Week 🗣️ - Basic MLs (Linear Regression and GBDT)
These two models are basically the bread-and-butter of prediction and are used for prices, demand, risk scoring, and all types of forecasting.
- Linear Regression (LR) = the “clean baseline” almost everyone starts with
- GBDT (Gradient Boosted Decision Trees) = the “structured workhorse”
In as basic terms as possible…
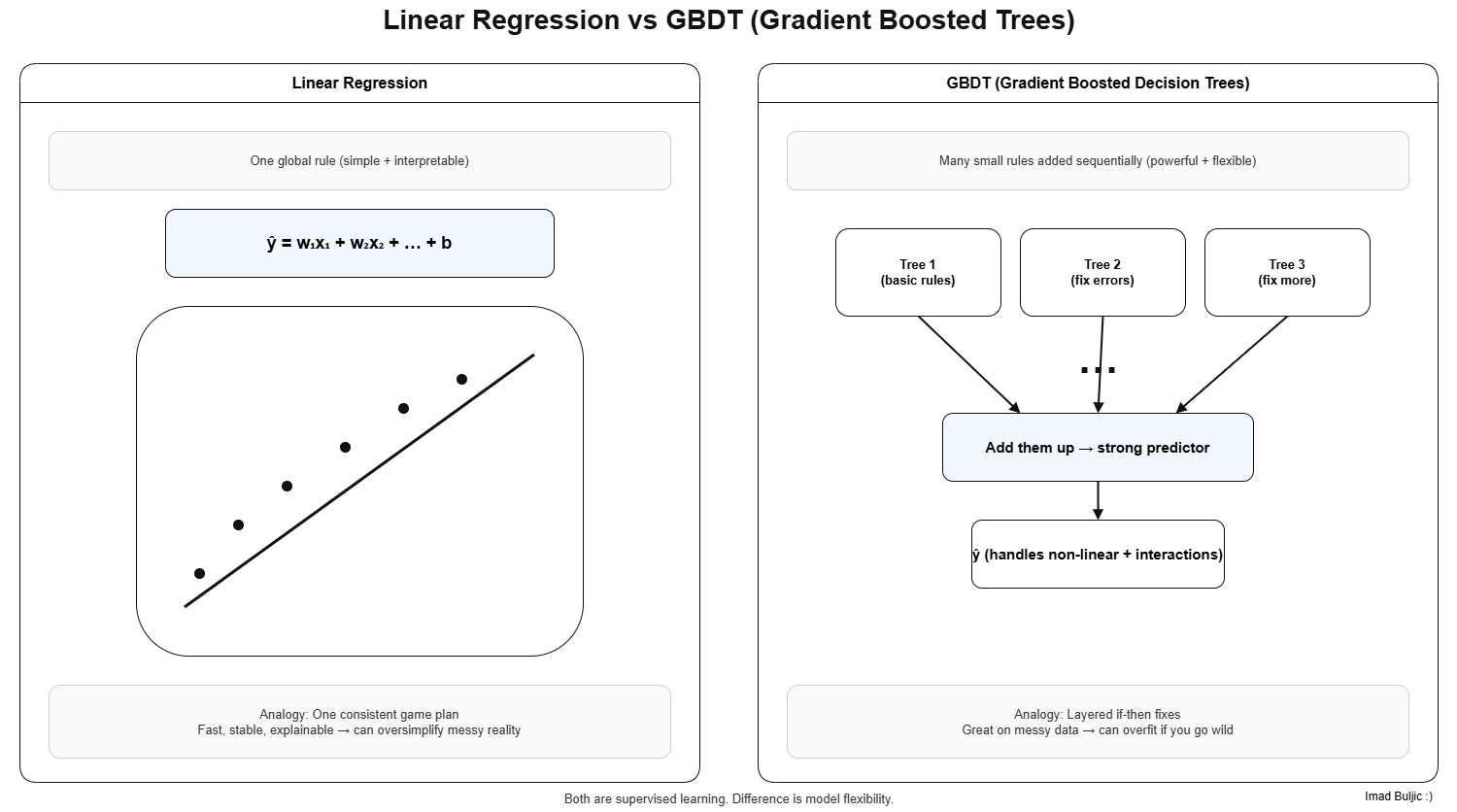
1) Linear Regression (LR) - one main rule
LR tries to learn one simple rule that maps your inputs to an output.
Say you want to predict requests per second that come to the app tomorrow based on: hour of day, day of week… LR learns something like:
- “Evenings usually add more load”
- “Weekends reduce load”
So it gives one clean answer: predicted RPS.
prediction = w₁·x₁ + w₂·x₂ + … + bias (dw about this too much tho)
So it’s answering: “If I increase feature X a bit, how much does the prediction move?”
2) GBDT - many small rules that stack into a strong brain
GBDT doesn’t use one rule. It builds many tiny rules.
Here, a decision tree is a small “choose-your-path” chart that makes a prediction by asking a few simple questions in order… some of those could be:
- “IF it’s Friday evening AND campaign is on → expect higher load”
- “IF it’s Monday morning AND no campaign → expect normal load”
- “IF it’s rainy day AND weekend → behavior shifts”
Then it combines these little rules into one final prediction. Each new tree focuses on the mistakes of the current model, so over time it becomes a strong predictor.
That’s why it’s called “boosting”: you’re boosting performance by iteratively correcting errors.
3) Strengths and weaknesses
a) When LR is a great choice:
- You want interpretability (you need to explain why)
- Relationships are roughly linear/additive
- You want a fast baseline + sanity check
- You’re feature-engineering manually (LR loves good features)
LR weaknesses:
- Can underfit: reality is often not linear
- Needs better feature engineering to capture complex patterns
- Sensitive to outliers / weird distributions (depends on setup)
b) When GBDT is a great choice:
- Your data has non-linear patterns (“it depends” relationships)
- Feature interactions matter (“A only matters when B is high”)
- You want strong results on tabular data without insane feature engineering
GBDT weaknesses:
- Can overfit if you go wild (depth/too many trees/high learning rate)
- Less “simple” than LR (you explain via feature importance/SHAP instead… Google this!)
- Typically heavier compute than LR (but still very practical)
Here’s another drawio image for this 🙃