80/20 Of The Week 🗣️ … Partitioning and Sharding
There’s a whole science behind these two! It’s a design decision that can make your system fly… or haunt you later.
There are a couple of key concepts for this so let’s go through them quickly
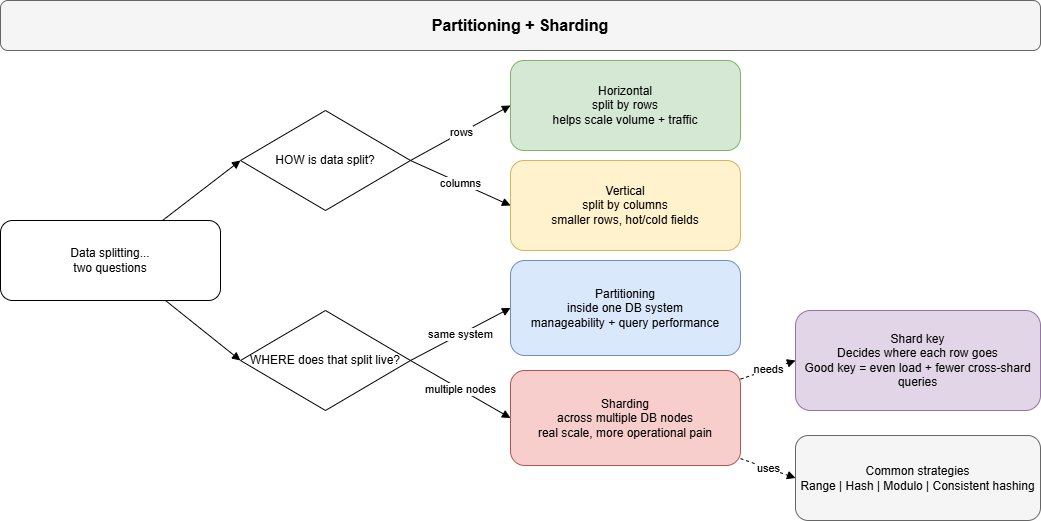
1) Horizontal vs Vertical data splitting
- Horizontal partitioning = split by rows Example: users with IDs 0–999,999 in one partition, 1,000,000+ in another
- Vertical partitioning = split by columns
Example: keep
id,name,emailin one table, and move heavier or less frequently used columns likebio,avatar,settingselsewhere
Essentially:
- Horizontal splitting helps with scaling data volume and traffic
- Vertical splitting helps reduce row size and isolate hot vs rarely used fields
2) Partitioning vs Sharding
These describe where that split happens.
- Partitioning = inside one database (same DB instance)
- Sharding = across multiple databases/nodes
Partitioning improves manageability and query performance. Sharding gives you real horizontal scale, but also adds operational pain such as rebalancing, consistency tradeoffs, harder migrations and so on and so forth (more on this in future).
3) Shard key
Your shard key is what decides where each row goes to! Good shard key:
- evenly distributes traffic (no hotspots)
- avoids cross-shard queries
- matches your access pattern
Bad shard key = “one shard is dying while others are chilling” Classic hotspot: sharding by country, date, or anything super skewed.
4) Sharding strategies
A) Range-based
(like userId 1–1M on one, 1M–2M on other…) Easy to understand, but can create hotspots because certain ranges could be queried more than others.
B) Hash-based
Distributes well, but is less intuitive to inspect/debug.
C) Modulo hashing
hash(key) % N
Simple, but painful when the number of shards changes… N here is the number of shards that you have.
D) Consistent hashing (ring)
Adding/removing nodes moves only a small portion of keys. Better for elastic scaling (usually with virtual nodes to balance load, we gon talk about this later on since it’s a topic of its own).
Although these concepts sound simple, sharding is rarely hard because of hashing itself. It becomes hard because of rebalancing, query patterns, bad shard keys, and the operational mistakes that only start hurting once you scale in production!