80/20 Of The Week 🗣️ … Idempotency and Resilience in systems (how to use “retry” properly)
I swear these are “simple” to understand the basics of but just sound tough xD
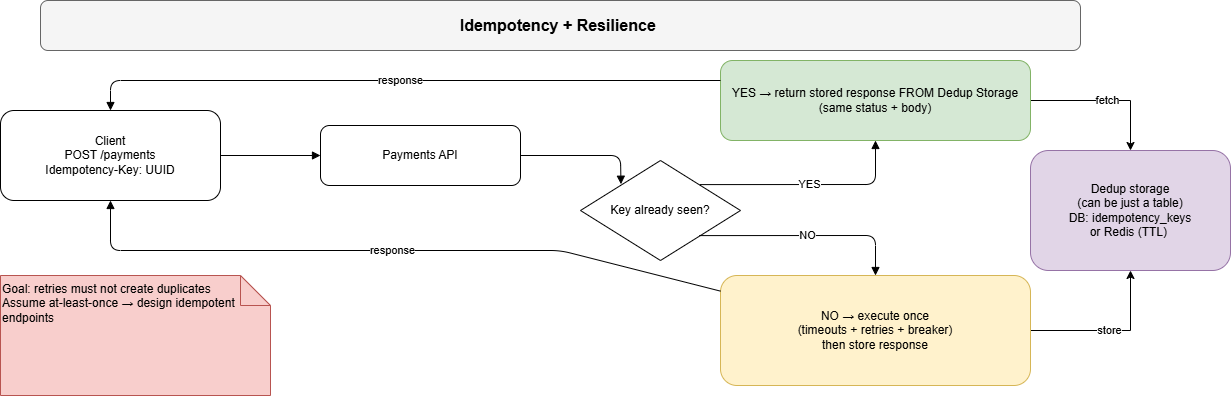
Let’s say an issue occurs in the system and a timeout happens. Client retries. And then… you charge the card twice or you order the same thing from Temu basket twice 😭
That’s why idempotency exists:
Idempotency = same request 100x → same result 1x… that is basically it…
How it works in real systems (simple)
Client sends an Idempotency-Key (usually a UUID) with a “dangerous” request like:
POST /payments, POST /orders, POST /transfers… basically FINAL steps of operations like orders or similar.
Server does this:
- Look up the key in dedup storage
- If it exists → return the same stored response (status + body)
- If it doesn’t → process once, then store the result
And yes… dedup storage can literally be just a table.
Example: idempotency_keys table (Postgres / MySQL / Oracle)
key(Idempotency-Key)scope(userId + endpoint)request_hash(optional, for safety)response_status,response_bodycreated_at,expires_at(TTL)
Where do you store it?
- DB table 👍 (boring, durable, easiest to reason about)
- Redis 👍 (fast + TTL), but you must accept the tradeoffs (if Redis is flushed/restarted and you didn’t persist → duplicates can come back… you can use DB as a fallback tho)
Most teams do:
- DB as “source of truth”
- Redis as a cache (optional)
Retries are good… until they aren’t.
If you retry:
- without timeouts → threads hang and you waste resources
- without backoff + jitter → thundering herd / stampede… example, you put timeout as fixed 2 seconds and now you have like 14 threads retrying EXACTLY after 2 seconds so they cause locking (race conditions) or other issues
- without max attempts → infinite pain
- without circuit breaker → you DDOS your own dependency/service lol
Usual “minimal but solid” combo:
- Timeouts (client + server)
- Retry with exponential backoff + jitter
- Circuit breaker (stop the bleeding)
- Bulkhead (isolate thread pools)
- Rate limiting (protect the system)
Quick consistency note
The moment you have retries + queues + async workflows, you’re living in “duplicates can happen” land.
So your safety net becomes:
idempotency + good retry policy + clear consistency expectation (strong vs eventual)
If you build big systems, assume the worst and design for it 😄
ALSO… “idempotent” means: the ability of a system to produce the same outcome, even if the same file, event or message is received more than once… shout out to Google!